



理解張量之前,需要先討論向量Vector和純量Scalar的意義。向量的定義在國中階段我們簡單講就是帶有方向與大小的量,用來表達一些物理狀態,例如方向朝下,大小9.8重力的加速度。或是像一個朝某方向作用的力,也是帶有大小和方向。為了方便,且更清楚嚴謹的拿向量來描述物理量,我們可以利用預先固定好的方向和大小來表達基本的計算單位,舉例來說我們可以在三維度的笛卡兒坐標系裡面,使用方向指向x軸,1單位長度、方向指向y軸,1單位長度,以及方向指向z軸,1單位長度的單位向量來共同描述在空間中任一個向量。
直觀一點來說,我們需要帶有大小方向兩種抽象概念的向量來幫我們描述現實世界的物理量,但這個向量,為了方便計算,通常又是由參考坐標的單位向量所重新描述。例如說指向地心90度垂直的重力加速度9.8這樣的向量,透過笛卡爾三維座標系的單位向量(X,Y,Z)可以改寫成(0,9.8,0)。這時候的n維向量是參考座標系的維度大小。
但有些時候,要表達的物理量比較複雜,沒辦法單純靠大小和方向兩個性質就描述出來。舉例來說,一個物體受外力作用,產生對外部反作用的抗衡力量,即為應力,是一整個面的力量,而表達平面這個概念需要用一個法向量和一個點來表示,表達力量又需要一個參數,如此一來原本的向量不夠表達(值得注意的是,即使增加n維向量的維度,只是改變參考系的單位向量數量,描述的性質還是只有大小與方向這兩種屬性)。於是張量的概念被提出來,多種向量當作基本單位描述的物理量,就是張量。舉例來說,一張數位圖片就是很典型的例子:一個圖片由像素矩陣所構成,而每一個像素又需要靠RGB色彩空間的三個基本單位來描述一個色彩向量。舉例5*5的彩色圖片[5*5*3]如下圖
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
即使我們把(R,G,B) 三維降低維度改成(R+G,G+B)兩維度,還是需要25個(R+G,G+B),如下圖:
|
|
|
|
|
||||||||||
|
|
|
|
|
||||||||||
|
|
|
|
|
||||||||||
|
|
|
|
|
||||||||||
|
|
|
|
|
改變單位向量的數量(從3->2),並不會影響需要5*5個資料來表示圖片。從這裡面就可以具體看出張量的數量(25),和一個向量的維度數量(2 or 3)是兩件事情。而,這組資料包含水平5個,垂直5個,以及色彩向量(R,G,B)。總共三個屬性,我們就定義其階數為3。當資料僅有水平5個,垂直5個(灰階圖片),則階數為2,所以會看到有些資料直接寫矩陣就是階數為2的張量。同理,向量,是階數為1的張量,純量的階數為0。
如果用電腦程式語言的表示方式,純量即為純變數[1],向量則可用陣列[1,2,3]表示,階數為2的張量可以用二維陣列:
[[1,2],
[3,4]] 表示,
而階數為3的張量,舉例來說像是:
[ [[R,G,B],[ R,G,B],[ R,G,B]],
[[R,G,B],[ R,G,B],[ R,G,B]] ,
[[R,G,B],[ R,G,B],[ R,G,B]] ]
TensorFlow 的名稱,凸顯了這個框架的兩個重要性質,靜態的資料結構設計成Tensor張量,能夠一次存放多屬性的資料,這讓我們可以用張量來描述我們要讓電腦進行機器學習的物件,像是一張包含RGB的彩色圖片。另外一方面Flow,則是表達運算的動態路徑流,TensorFlow利用Graph來表示Tensor的運算加工流程,以方便產生自動微分AD,這是執行反向傳播來修正類神經網路權重的核心過程。所以如果有人問你,TensorFlow的原理是什麼?她最重要的特點是什麼?我認為答案已經在「Tensor」「Flow」這兩個詞彙上面了。

強化學習起源於模仿人類決策依賴多巴胺(爽)的獎懲機制,是獨立於監督式學習,非監督式學習的第三種機器學習模型。強化學習是一種決策的學問,在許多領域之中都有相關的分支,因此強化學習本質上是跨領域的技術。
完全可觀測的情況之下,我們的模型稱為MDP
有很多情況是不可完全觀測環境狀態的,例如玩撲克牌的代理人,牌組的資訊是被隱藏的。(因為會被蓋住)或是像只有攝影機,無GPS無地圖的機器人在環境中探索時,有部分的空間資訊也是當前的機器人無法同時觀測的。
Policy 策略: 代理人的行為函數,即狀態-行為的映射 a=可以是固定的函數,也可以帶有隨機的行為映設,即在某狀態做為條件之下,做出某行為的機率有多少的條件機率。
強化學習:未知環境運作,透過不斷嘗試,利用策略和模型,求取最大利益
規劃:已知環境的運作,求取最大利益
探索:放棄當前已知最佳選擇,反而去嘗試其他不曾作的行為,來了解環境,為了之後能求取最大利益
當強化學習的內部模型能完美描述外部環境時,就能做預先規劃,等於是已知環境的遊戲規則。
強化學習是一種利用獎勵互動的機器學習技術,廣泛應用在機器人學,遊戲類的學習上。
課程資訊:http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html 課程影片: https://www.bilibili.com/video/av9831889/ 課程簡報: https://github.com/applenob/rl_learn/blob/master/slides/Lecture%201%20-%20Introduction%20to%20Reinforcement%20Learning.pdf
#本文為強化學習讀書會之第一堂課程的講稿
以下介由紹NVIDIA 公司的GPGPU(通用目的圖型處理器)的開發函式庫-CUDA(Compute Unified Device Architecture)在Linux環境下的安裝流程,這是學習GPGPU編程的第一步。
這個步驟要確認硬體設備的GPU適用的CUDA版本。GPU本身就會有驅動程式的編號,需和CUDA的版本搭配。可以利用以下指令查詢GPU驅動程式
$ sudo ubuntu-drivers devices

(本表來自官方針對社群提問的回答當中的一個stackoverflow上的解答)
到以下網址選擇要安裝的CUDA版本( https://developer.nvidia.com/cuda-toolkit-archive )
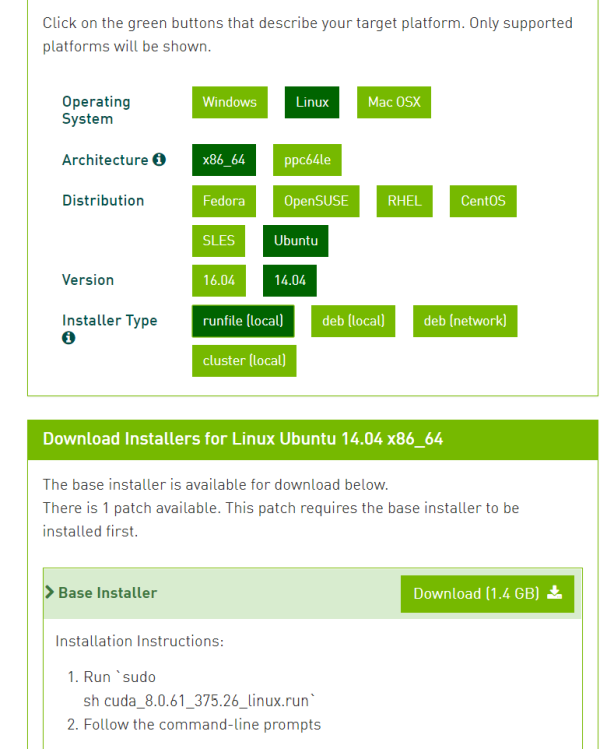
請按照你電腦的硬體選擇正確的安裝檔案,我電腦為例,使用Linux Ubuntu版本14.04,並且為了減少負擔,直接使用官方寫好的安裝腳本 (.run)
Ctrl+Alt+F1 後登入終端機,並執行以下指令關掉圖形介面
$ sudo service lightdm stop
用cd 指令變更路徑到下載的腳本位置,然後執行
$ sudo sh cuda_8.0.61_375.26_linux.run
(注意腳本名稱不一定和我相同,記得修改)
跑起來之後會要求你閱讀使用條款,按Enter或空白鍵可以把條款往下拉,到最後會出現是否同意,輸入 accept 即可。接下來會出現各種需要同意的項目,同意之後,輸入Y。
如果安裝失敗,提到有驅動安裝不完整的狀況,可能需要用以下指令先把驅動程式清乾淨再裝
$ sudo apt-get purge nvidia-*
安裝成功之後更新重啟電腦,然後去以下目錄編譯測試程式
$ cd /usr/local/cuda版本號/samples
$ make –j8
編譯完成之後,再
$ cd ./0_Simple/simplePrintf
底下執行
./simplePrintf
正常印出訊息表示執行成功。

01 DP動態規劃
02 Beam search集束搜索
The Harpy Speech Recognition System , Lowerre , 1976
03 EM最大期望算法
04 GMM高斯混合模型
05 Viterbi 維特比算法
01 HMM 隱式馬可夫鏈
Japanese word segmentation by hidden Markov model , Constantine P. Papageorgiou , 1994
02 HHMM 階層隱式馬可夫鏈
HHMM-based Chinese lexical analyzer ICTCLAS , HP Zhang , 2003
03 MEHMM 最大熵隱式馬可夫鏈
A Maximum Entropy Approach to Chinese Word Segmentation , JK Low , 2005
04 CRF 條件隨機場
Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data , John Lafferty , 2001
05 AP 平均感知器
Discriminative Training Methods for Hidden Markov Models:Theory and Experiments with Perceptron Algorithms , Florham Park , 2002
06 SSVM 結構化支持向量機
Chinese Word Segmentation by Classification of Characters – ACLCLP, CL Goh , 2005
07 壓縮分詞
A Compression-based Algorithm for. Chinese Word Segmentation , WJ Teahan , 2000
08 EM自我監督分詞
Self-Supervised Chinese Word Segmentation , Fuchun Peng , 2001
09 基因分算法分詞
以遺傳演算法為基礎的中文斷詞研究 , 陳稼興 , 2000
本列表論文檔案下載:https:/goo.gl/TTxXtV

這是我對自己學習知識的一份思想總結,也是一個學習技法的操作手冊
學習知識是多數人在20歲以前花費最多時間和金錢去做的事情,它佔用我們絕多數的時間和精神,卻鮮少人思考這件事本身的意義和方法。因此在我談論循環學習法之前,先分析學習知識的目的性。學習知識最直覺的用途是工作,我們藉由學習一項專業知識並將之轉化為技能,利用時間與技能形成產出來賺取金錢,或是其他價值,這是多數人追求知識的目的。另外有一些人,追求知識的同時會對知識本身提出疑問,並且藉由文獻,數據,實驗和辯論來回答這些疑問,從而改進一些方法和理論,這些人並不是在追求訓練知識本身,而是在試圖建造知識本身的分支和延伸。這種目的對於學習知識的態度更為複雜,並不只是熟嫻一項技藝,而是花更多力氣探索和辯證,在人類的知識金字塔上堆疊,創建更多的項目。第三種學習知識的目的是質疑知識本身,並且試圖回答人類與世界絕大多數的為什麼。例如學習微積分來回答為什麼棒球投擲出去的末速度的數值會是那樣?
這三種追求知識的代表各有千秋,第一種追求知識的目的做到極致,我認為以日本職人(Shokunin)為代表,並把追求時間與技能本身昇華成目的,以熟練為精神指標。而第二種人,不停的試圖改進技術,推動文明的前進。近代史上我認為以西方工業的研究人員與發明家為代表,具體來說像是尼古拉·特斯拉這類的開創者為代表,他們以實驗為精神指標。而第三種人,則是以基礎科學的建立者為代表。這類型得追求在於知識本身的純粹性,希望探究事物原理,而不在當下考慮實用面,應用面。近代史我認為以西方科學家為代表,例如牛頓,愛因斯坦等人。他們以辯證,論述為精神指標。這三種追求知識得目的是最為常見得原因,而我們必須思考的是,我們為何而學?我們追求知識的目標是哪一種?這三種本質上對人類的文明在不同場景下都有不同的貢獻,但是驅動學習的初衷和對知識的掌握要求不儘然相同。
我認為在學習任何一項知識之前,必然需要經過思考學習得目標為何?不同的戰略目標會有各自對應的戰術方法,明白自己的學習目的才是真正為學習這件事情負責任的態度,否則如同多數人對於知識都處於被動的接收狀態,都不具有學習的主體性,無疑是浪費自己的學術生涯寶貴的時間,也浪費國家資源對於學習知識本身的挹注,甚至可以說是非常可恥的。
最後,本文所探討的學習方法其精神強調能夠利用知識執行第二類與第三類的知識開拓工作,所以實驗與辯證精神是遠大於反覆練習操作知識的,因此想將此技法推薦給從事類似事情的研發人員。
蘇格拉底法是西哲蘇格拉底的學習技巧。具體來說,教師並不會給予學生問題的答案本身,而是不斷拋出問題讓學生加以批判,辯證,並藉由教師一連串的問題構築出知識網路。此法的優點在於讓學習者能對知識本身的連結性和脈絡會更加清晰,也更有能力對知識提出問題和實驗,形成研究知識的慣性。缺點在於,耗時耗力之外,引導者本身對於知識體系的連結能力要夠強,才足以勝任引導者布局知識的角色。對於研究者而言,對知識提出問題是很重要的過程,此法是所有科學的必然。
費曼技巧來自於美國物理學學家理查.費曼(Richard P. Feynman)的設計。具體的操作步驟如下
Step1:把你想學習的知識看完之後,把概念寫在紙上。
Step2:想像一個小孩子的學生,想像他的年齡,已知知識等等。
Step3:用自己的說法,簡單易懂的詞彙把這份知識教給這個想像中的學生。
Step4:如果發現自己無法明白的說出所以然,那說明知識理解不夠清楚,重複1-3步驟直到完全學會為止。
筆者認為此法的優點有:完全學會之後能夠極大化的增加對知識的操作能力,也就是說,面對現實世界的問題會比較有足夠能力去使用此知識來解決問題。缺點則是耗時耗力,且對於訓練第一型解固定題型熟練本身並沒有直接幫助。總結來說,對於研究人員的知識可操作性能夠很大程度的提升,因此是一個重要的學習技巧。
如果將蘇格拉底法語費曼技巧結合在一起,會形成一個辯證循環,我認為這是一個能更大強度提升知識拓展工作的能力。具體操作方法如下
Step1:先把要學習的知識概念寫在一張A4紙上,把有關係的概念用線段連起來。
Step2:想像自己是引導教師的角色,開始一連串的拋出問題,並且假設這位引導員的知識不足,但所有的疑問按照Step1的問題走。
Step3:用自己的語言,簡單的詞彙回應問題,並試圖講解給想像中的引導教師。
Step4:假想一些現實世界的問題,帶入情境去思考,然後由引導教師拋出問題,想辦法用目前的知識去解決它。
Step5:重複1-4步驟直到完全理解為止。
此方法的關鍵點在於,同時假設兩個身分,一個負責建立知識網路和提出詰問,另一個負責用淺顯易懂的方式回答問題,教導提出問題的角色。同時於這兩種身分當中切換需要利用一點想像力,最簡單的啟動方式就是在準備切換角色之前先閉上眼睛,默數10秒,在腦海裡默想角色的圖像(Image),你可以替這兩種角色假設一些具體的細節,甚至乾脆不同性別,膚色與文化背景,然後想像一個具體的樣貌,來幫助操作。另外,很多知識本身是巢狀的,也就是因為A 包含B
,B包含C,所以為了解釋A必須要先討論C再討論B最後才討論A。這種遞迴得知識網路詰問與學習,也是此方法能夠深度的學習的關鍵。
由於我們事先設計了提問和回答方兩種角色,因此在辯證的過程當中,可以同時訓練提問和利用知識回答的兩種關鍵能力,因此可能有機會提升利用知識解決問題的能力。
綜合方法的每個環節也可以利用一些工具來輔助,舉例來說像是回答問題的時候,弄一個白板來講解可能效果會更好。還有像是把講解的過程乾脆直接實施在讀書會或是一些實體的教育經驗上。或許這些更具體的操作可以讓自己學會更多。
數學類型的知識往往會用公式來簡潔的表達一連串的抽象計算流程,例如像是連續加法利用Sigma來表示。抽象演算是數學解決問題的技巧,流程大約是把現實世界的問題傳送到數學的抽象空間中進行演算,透過化簡與分解,通常能夠取得一些方程式來回答現實世界的問題。換言之,抽象演算是數學的利器,依賴抽象演算不會出差錯的原則,人類大腦可以暫時不管實際發生什麼事情,只需要專注在演算本身的流程即可。
然而,當數學演算必須展開成具體流程並且交給演算法來實現到程式語言時,工程師必須精確的了解演算的每一個環節發生什麼事情,才能把計算流程轉譯到電腦程式上,這時候數學符號的簡潔優勢便成為多數工程師的學習與工程阻力。為了解決這個問題,除了綜合方法之外,我們也可以利用實際帶入數字去拆解演算法本身的運作流程。這時候加入一個學習環節就是把數值帶入公式,一個個步驟像影格一樣拆解,這個過程一般稱為手解、手算或是手撕。這樣的流程優點是能夠消除實作的抽象阻力,將數學公式抽象具體化,動態化。缺點是極其耗時耗力。這個技巧對於資訊科學實作有一定程度的幫助,對於資訊科學相關的研究人員,是值得使用的一種學習技巧。
本文所討論的學習方法是筆者本身所使用的學習方式,對於提升知識的可操作性有很大的幫助。學習的過程耗時耗力,但可視為一種長期投資,需要時間去累積知識網路的複雜性和可操作性。對於研究人員而言,知識可操作性是驅動科學研究的核心能力,其重要性並不亞於觀察現實世界的問題,撰寫論文與執行實驗的能力。這篇文章一共介紹了四種方式來學習(蘇格拉底,費曼,前兩者綜合,以及手算),學習的目的是理解知識本身,並且增強知識解決問題的能力,以及開拓知識網路的能力,希望這篇文章能夠給讀者帶來學習高等教育的啟發,讓台灣的研發力量能夠更大程度的提升!


寫在前面:這篇文章是用來幫助理解貝氏分類器的前置作業的一篇直觀理解的文章 ,有鑑於許多人對數學符號不熟悉,因此我希望用稍微故事一點的方式說明。
夜市是台灣特殊的文化,講到夜市,除了吃之外,最讓人津津樂道的還有各種帶點運氣味道的遊戲。舉例來說,像是用超 市買的到的紅標米酒的空罐擺滿
一個約莫四五個人站的小區塊,老闆總是笑吟吟的拿著擴音器喊著價,一組圈圈50元,套中玻璃瓶有賞,還有類似的提供一組飛鏢,射破氣球有賞。類似這種遊戲總是能吸引過客駐足,雖然大部分的時候沒看見什麼人抱走大獎,不過也是一個令人感到親切的夜市文化。提到這個有趣的文化,我們就利用這個回憶來做一個思想實驗。這會幫助我們直覺的理解貝氏分類器的原理。
好進入正題,首先我們想像一下一個特別的射飛鏢遊戲,如下圖,我們用一隻飛鏢去射眼前藍色和紫色圓的區域,為了保證隨機性,我們只能閉上眼朝前面射出,因此我們不會預先知道飛鏢可能落入的範圍。

直覺告訴我們,射中紫色的機會一定比藍色的大,這是為何呢?因為面積較大,比較有機會中。因此,就這個衡量飛鏢落入藍色或紫色的範圍的可能程度,我們就用面積表示。此時第一個公式出現了,我們用P(X) 且X=藍或紫 表示射中藍或紫的機率大小。基於射中機率正比於藍或紫的面積,反比於全部面積,可以寫成以下公式:
P(藍)=藍色面積/全部面積 P(紫)=紫色面積/全部面積
這個公式就是古典機率公式,事件發生的機率=該事件的所有排列組合/全部事件的排列組合。
接下來發揮一點想像力,如果們的紫色標靶和藍色標靶是可以被射破的,現在我們把此色標靶往前面挪,藍色標靶往後,類似下圖的側視立體圖。這樣一前一後的標靶,讓我在玩一次射飛鏢。如果我們在飛鏢已經射入紫色區域的附近,但還沒飛到藍色區域的時候我們在此刻觀測飛鏢的位置會得到三種結論:
飛鏢A-射破紫色區域,也會射到藍色區域的飛鏢,飛鏢B-射破紫色區域但不會射到藍色區域的飛鏢,飛鏢C-沒有射中紫色區域也不會落入藍色區域的飛鏢。

我們感興趣的是飛鏢的狀態。這種已經確定射破紫色區域,然後會落入藍色區域的機率如何計算?根據前面面積的想法,我們可以說這樣的機率等於紫且藍的面積大小除以紫色面積(假設觀測者只知道飛鏢已經穿過紫色區域,但不知道未來會不會掉進藍色區域)。第二個公式出現了,這就是所謂的條件機率
P(藍|紫)=藍且紫的面積/紫色面積
數學的嚴格定義如下:
若A,B為樣本空間中的兩事件,且P(B)>0 , 則在給定B發生之下,A的條件機率以P(A|B)表示, 定義為P(A|B)=P(A^B)/P(B)
最後,我們再來看如果我們直接去看既穿過紫色區塊且又穿過藍色區塊的飛鏢的機率,我們直覺上還是用第一個公式的方法,藍且紫的面積/全部面積。數學上稱之為聯合機率 。稍微整理一下這三種面積計算機率的方法:
P(紫)=紫面積/全面積 P(藍|紫)=藍且紫的面積/紫色面積 P(藍^紫)=藍且紫的面積/全部面積
可以發現
P(藍|紫)* P(紫)=(藍且紫的面積/紫色面積)*(紫色面積/全面積)= P(藍^紫)
P(A^B) = P(A|B) *P(B)=P(B|A) *P(A)
P(A|B) *P(B)=P(B|A) *P(A)
得到
貝氏定理 P(A|B) = P(B|A) *P(A)/ P(B)
寫到這裡,如果對貝氏定理的數學計算有興趣的話,可以參考一位教授周志成教授寫的文章 條件機率與貝氏定理 會有更數理的抽象計算。 我會在下一篇文章用故事的方式來講貝氏分類器的範例。

以3分類作範例:
1.混淆矩陣(Confusion matrix)
| 預測為0 | 預測為1 | 預測為2 | |
| 實際為0 | 2 | 2 | 0 |
| 實際為1 | 1 | 2 | 0 |
| 實際為2 | 0 | 0 | 3 |
(數據來源 http://gabrielelanaro.github.io/blog/2016/02/03/multiclass-evaluation-measures.html )
混淆矩陣(預測類別i,實際類別j)的值=分類器預測類別為I,而實際類別為j的數量
Diagonal(Class)=實際為Class且預測為Class的數量=矩陣斜對角(紅字)
2.混淆矩陣擴增
| 預測為0 | 預測為1 | 預測為2 | 第n類的實際總數
(sum of each row) |
|
| 實際為0 | 2 | 2 | 0 | 2+2+0=4 |
| 實際為1 | 1 | 2 | 0 | 1+2+0=3 |
| 實際為2 | 0 | 0 | 3 | 0+0+3=3 |
| 第n類的預測總數
(sum of each column) |
2+1+0=3 | 2+2+0=4 | 0+0+3=3 | 實際總數(Sum all) =4+3+3
=10 |
3. Precision(精密度) (Positive Predictive Value)
預測為正的樣本中有多少預測對了
Precision(Class)=Diagonal(Class)/ Sum of each column(Class)
Precision(0)=2/(2+1+0=3)=2/3
Precision(1)=2/(2+2+0=4)=2/4
Precision(2)=3/(0+0+3=3)=2/3
4.Recall(召回率)
真實正的樣本有多少被預測對了
Recall (Class)= Diagonal(Class)/ Sum of each row(Class)
Recall (0)= 2/(2+2+0=4) =2/4
Recall (1)= 2/(1+2+0=3) =2/3
Recall (2)= 3/(0+0+3=3) =3/3
5.Accuracy(準確度)
有多少比例的樣本預測對了
Accuracy=Sum All Class of (Diagonal(Class))/ (Sum all)
Accuracy=(2+2+3)/ 10
6.F1值 (綜合考量 Precision與Recall)
F1(Class)=2*Recall(Class)*Precision(Class)/ (Recall(Class) + Precision(Class))
7.True positive rate(Sensitivity)
(預測為Class且實際為Class數量)/Class實際總數
TPR (Class)= Diagonal(Class)/ Sum of each row(Class)
TPR (0)= 2/(2+2+0=4) =2/4
TPR (1)= 2/(1+2+0=3) =2/3
TPR (2)= 3/(0+0+3=3) =3/3
8.True negative rate (Specificity)
(預測為不為Class且實際為不為Class總數量)/不為Class實際總數
TNR (Class)= Sum of (Diagonal(Not Class))/ Sum of (Sum of each row(Not Class))
TNR (0)= (2+3)/(3+3=6) =5/6
TNR (1)= (2+3)/(4+3=7) =5/7
TNR (2)= (2+2)/(4+3=7) =4/7
9.False positive rate
(預測為Class且實際為不為Class總數量)/不為Class實際總數
TNR (Class)= (Sum of each column(Class)- Diagonal(Class))/ Sum of (Sum of each row(Not Class))
FPR(0)=(1+0) /(3+3=6) =1/6
FPR(B)=(2+0)/(4+3=7)=2/7
FPR(C)=(0+0)/(4+3=7)=0/7
10.ROC(Reciver Operating Characteristic) 曲線
X軸:FPR (0~1)
Y軸:TPR (0~1)
曲線圖左上角最佳(FPR最低, TPR最高)
AUC (曲線下麵積越大越好)
離散估計面積:
將每輪分類器的ROC點座標排序 共n個
第n個座標與第n-1個座標由底下公式估計面積:
Area(n)=(Xn-Xn-1)*( Yn+ Yn-1)/2
加總n=1~n

(1-0)*(1+0)/2=0.5
(2-1)*(3+1)/2=2
(4-2)*(4+3)/2=7
Sum=0.5+2+7=9.5
11.PR曲線
X軸:Recall (0~1)
Y軸: Precision (0~1)

近期迴響